Dear subscribers,
I hope you are having a great week! Sorry for the big newsletter but there is lot to cover!! Please read full newsletter on my site if in case it gets clipped by Gmail!
New Models & 🔥 research:
TableLLM: A new LLM model with 13 billion parameters specifically designed for dealing with tabular data
Eurus: Set of open source models out performing GPT-3.5 Turbo and other large models in many categories.
HyperCLOVA X: A family of large language models that have been trained on a balanced mix of Korean, English, and code data.
Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems [Explained below]

🤔Problem?:
This research paper addresses the issue of limited interaction between humans and artificial intelligence (AI) in multimodal large language models (MLLMs), which hinders their effectiveness.
💻Proposed solution:
The research paper proposes a solution called SPHINX-V, which is a new end-to-end trained MLLM that connects a vision encoder, a visual prompt encoder, and an LLM. This model allows for various visual prompts (such as points, bounding boxes, and free-form shapes) and language understanding, enabling a more flexible and in-depth response.
📊Results:
The research paper demonstrates significant improvements in SPHINX-V's capabilities in understanding visual prompting instructions, particularly in detailed pixel-level description and question-answering abilities. This suggests that SPHINX-V may be a more effective and versatile MLLM for interacting with humans.

🤔Problem?:
The research paper addresses the issue of efficiently handling tabular data manipulation tasks in real-world office scenarios.
💻Proposed solution:
To solve this problem, the paper introduces TableLLM, a large language model with 13 billion parameters specifically designed for dealing with tabular data. The model is trained using a distant supervision method that includes a reasoning process extension strategy to help the model better understand reasoning patterns. Additionally, a cross-way validation strategy is used to ensure the quality of the automatically generated data. To evaluate the model's performance, a benchmark tailored to document and spreadsheet formats is created, along with an evaluation pipeline capable of handling both scenarios.
📊Results:
The paper reports that TableLLM outperforms existing general-purpose and tabular data-focused LLMs in thorough evaluations.

🔗 Model: https://github.com/OpenBMB/Eurus
💻 Contribution: Eurus, a suite of LLMs that have been finetuned from Mistral-7B and CodeLlama-70B. These models have been optimized for reasoning by incorporating a newly-curated alignment dataset called UltraInteract, which includes diverse planning strategies, multi-turn interaction trajectories, and pairwise data for preference learning. This allows Eurus to achieve state-of-the-art results on various reasoning benchmarks.
📊Results: Eurus-70B outperforms GPT-3.5 Turbo !! Eurus-70B beats GPT-3.5 Turbo in reasoning through a comprehensive benchmarking across 12 tests covering five tasks, and achieves a 33.3% pass@1 accuracy on LeetCode and 32.6% on TheoremQA, two challenging benchmarks, substantially outperforming existing open-source models by margins more than 13.3%.

🤔Problem?:
The research paper addresses the problem of toxic language and speech in digital communication, and the negative impact it can have on individuals and society.
💻Proposed solution:
The research paper proposes to solve this problem through text detoxification, which is a process of paraphrasing toxic text into a neutral register. This is achieved through the development of various text detoxification methods, such as detoxification of Large Language Models (LLMs) and toxic speech combating in social networks. Additionally, the research paper introduces MultiParaDetox, a pipeline that automates the collection of parallel detoxification corpora for multiple languages. This pipeline utilizes different text detoxification models, including unsupervised baselines and fine-tuned models on the collected parallel corpora, to achieve state-of-the-art results for detoxification in any language.

🤔Problem?: The research paper addresses the challenge of efficiently serving multiple large language models (LLMs) in organizations. This is due to the varying popularity of LLMs, which poses significant challenges for existing approaches.
💻Proposed solution: The research paper proposes MuxServe, a flexible spatial-temporal multiplexing system, as the solution to this problem. MuxServe works by colocating LLMs based on their popularity to multiplex memory resources. It also leverages the characteristics of prefill and decoding phases to separate and flexibly colocate LLMs to multiplex computation resources. MuxServe also includes a novel placement algorithm and adaptive batch scheduling strategy to identify optimal colocations and maximize utilization. Additionally, MuxServe designs a unified resource manager to enable flexible and efficient multiplexing.
📊Results:
The research paper has achieved significant performance improvement. MuxServe can achieve up to 1.8 times higher throughput or process 2.9 times more requests within 99% SLO attainment.

💻Proposed solution:
The research paper proposes a framework called SGSH (Stimulate GPT-3.5 with Skeleton Heuristics) to enhance KBQG (Knowledge Base Question Generation). This framework incorporates "skeleton heuristics" which provide fine-grained guidance to stimulate large language models, such as GPT-3.5, to generate optimal questions. It works by automatically constructing a skeleton training dataset using ChatGPT, then using a soft prompting approach to train a BART model to generate the skeleton associated with each input. Finally, the skeleton heuristics are encoded into the prompt to incentivize GPT-3.5 to generate desired questions.

💻 Solution: The research paper proposes a method called Highlight-CLIP (HL-CLIP) which fine-tunes a pre-trained multimodal encoder and uses a saliency pooling technique to detect highlights in videos. This method works by leveraging the pre-trained knowledge embedded in the multimodal models to improve performance in the highlight detection task.

🤔 Problem?:
The research paper addresses the problem of efficient identification, verification, and interpretation of insights within the current chat-based interfaces of large language models (LLMs) for data analysis. This is a significant challenge for data analysts who rely on LLMs to generate data insights based on their analytic intents.
💻Proposed solution:
The research paper proposes an LLM-based multi-agent framework to automatically extract, associate, and organize insights along with the analysis process. This framework utilizes the capabilities of LLMs to perform complex reasoning and generate insights, and then organizes and presents these insights in a user-friendly manner. The proposed solution, called InsightLens, also visualizes the conversational contexts from multiple aspects to facilitate insight discovery and exploration.
📊Results:
The research paper does not mention specific performance improvements achieved by InsightLens. However, it is mentioned that a user study with twelve experienced data analysts demonstrated the effectiveness of InsightLens, showing that it significantly reduces users' manual and cognitive effort without disrupting their conversational data analysis workflow. This leads to a more efficient analysis experience for data analysts.

🤔Problem?:
The research paper addresses the issue of matching speech and text in multiple languages, with a focus on languages that do not have paired speech and text data.
💻Proposed solution:
To solve this problem, the research paper proposes using large language models (LLMs) to initialize multi-modal dual encoder (DE) retrieval systems. This means that the LLMs are used to create a shared embedding space for both speech and text data, allowing for cross-lingual matching. Unlike traditional methods, this approach does not require speech data during LLM pre-training, and instead leverages the LLM's multilingual text understanding capabilities to match speech and text in previously unseen languages.
📊Results:
The research paper reports a 10% absolute improvement in Recall@1 when evaluating their multi-modal LLM-based retrieval system on 102 languages, compared to previous systems trained explicitly on all 102 languages. This improvement is achieved despite the fact that the system was only trained on 21 languages. Additionally, the model also demonstrates cross-lingual speech and text matching, which is further enhanced by using readily available machine translation data.

🤔Problem?: Addresses the issue of hallucinations in LLMs
💻Proposed solution: Paper proposes an active learning framework called HAllucination Diversity-Aware Sampling (HADAS). It works by measuring and selecting diverse hallucinations in LLM outputs, specifically targeting errors in semantic frame, discourse, and content verifiability in text summarization. This selected set of diverse hallucinations is then used for annotations in active learning for LLM finetuning, reducing the need for costly human annotations.
Papers with database/benchmarks:
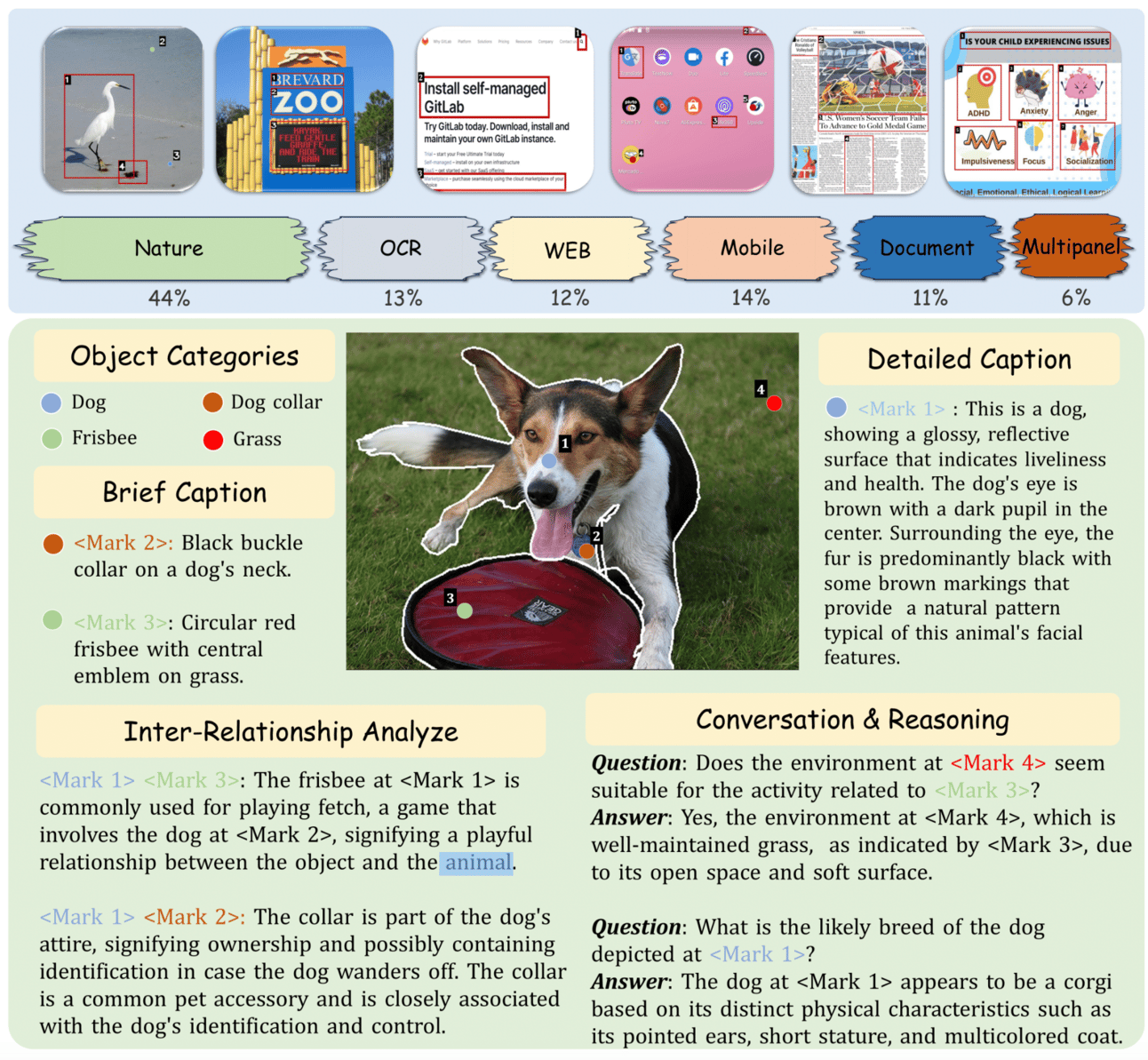
MDVP-Data: Multi-domain Visual-Prompt Instruction Dataset🔥🔥
A massive dataset (approximately 1.6 million multimodal dialogues) providing brief caption for each object categories in images.
LawInstruct, which covers 17 jurisdictions, 24 languages, and a total of 12M examples. The dataset can be used to accelerate the development of models with stronger information processing and decision making capabilities in the legal domain
Long-context LLMs Struggle with Long In-context Learning 🔥 - A new benchmark called LIConBench, which focuses on long in-context learning for extreme-label classification. Paper found out that except GPT-4 all models performance degrades when the context window exceeds 20K.

📚Want to learn more, Survey paper:
🧯Let’s make LLMs safe!!
Topic-based Watermarks for LLM-Generated Text - This paper proposes the use of a "topic-based watermarking algorithm" to embed detectable signatures within LLM-generated output. This algorithm generates tokens for the watermarked output based on extracted topics, using a pair of lists to specify which tokens to include or exclude.
🌈 Creative ways to use LLMs!! (Applications)
LLM-ABR: Designing Adaptive Bitrate Algorithms via Large Language Models [Using LLMs to to autonomously design adaptive bitrate (ABR) algorithm]
🤖LLMs for robotics:
